
In October, I had the wonderful opportunity to speak at the Confluent Current conference in New Orleans. In the talk, “Metadata: From Zookeeper to KRaft” we discussed what metadata for Apache Kafka is, how it is used, and how it evolved to be managed by different systems over the course of history.
We expanded on this premise to understand Apache Zookeeper’s early role in Kafka metadata management, functioning as a separate distributed system alongside each Kafka cluster. We noted the design flaws related to the usage of Zookeeper with Kafka, such as the administration and scaling of two separate distributed systems. KRaft, a Kafka-specific distributed consensus protocol based on the Raft algorithm, was introduced as a new system to bake metadata management into the brokers of each Kafka cluster.
With an understanding of these two systems, we delved into metadata migrations from Zookeeper to KRaft: dangers to avoid, and the recommendation to use a multi-step “dual write” approach for the most safety.
At the end of the talk, it was amazing to hear the number of questions from the eager audience. Many questions were from cluster operators seeking peace-of-mind when performing the potentially dangerous migration process, often with multi-cluster and multi-region considerations. Other questions were regarding the structure of Kafka metadata itself. In this blog post, we will expand on all of these topics to answer common questions about Kafka metadata.
What is Kafka Metadata?
When something is “meta”, it is often self-referential in nature. For example, metacognition is thinking about thinking, and metatheory is theorizing about theories. A favorite among software developers is metaprogramming, which is source code that generates other source code. Metadata is not as straight-forward; it is true that metadata is “data about data,” but it is important to ask what that means. In most scenarios, metadata is manually defined by the relevant domain: in this case, Kafka.
Kafka defines metadata as stateful data that is used for cluster management. Because each Kafka cluster is a distributed system, the metadata must also be distributed for maximum availability, failover, and consensus. Apache Zookeeper was the original distributed metadata management system for Kafka clusters, and KRaft is its successor.
The full structure of Zookeeper and KRaft will be discussed later, but for now, it is important to know that each will store metadata differently. For clusters that use Zookeeper, metadata is organized into a hierarchy of ZNodes. For clusters that use KRaft, a single-partition infinite-retention internal topic named “__cluster_metadata” is used for all metadata storage and consensus.
Specifically, Kafka metadata includes (but is not limited to):
- Topics:
- ID
- Name
- Partition Counts
- Retention
- Replication Factor
- Consumer Group Offsets (Zookeeper only)
- Brokers:
- ID
- Hostname
- Port
- Partition assignments
- In-Sync Replicas (ISRs)
- Cluster:
- ID
- Active Controller Elections
- Access Control Lists (ACLs)
Apache Zookeeper
To understand why Apache Zookeeper was originally adopted for usage with Kafka, put on your open-source hat and take a journey back to 2012. You are a systems designer challenged with creating a distributed, event-driven messaging protocol. There are two primary considerations: consensus of the cluster state, and the distribution of messages throughout the cluster.
Consensus of the current cluster state is important because the latest cluster metadata for topic names, replication, broker health, and other properties should be consistently accounted for. Internally, consensus is also required for maintaining the leader controller of cluster metadata. The distribution of messages throughout the cluster is important to prevent single-points-of-failure with replication, and to facilitate consumer event subscriptions.
Wouldn’t it be great if there was a pre-built open-source system to take the issue of consensus off your hands, with distributed leader election included? By using an existing system for consensus, Kafka development could instead focus on producers, consumers, topics, partitions, and other aspects of distributed messaging. That is exactly what Zookeeper offered. As a standalone open-source project, Zookeeper offers configuration management, cluster synchronization, and a naming registry out-of-the-box.
Zookeeper with < Kafka 0.9
In early versions of Kafka, before November 2015, metadata was used in a different way than modern Kafka developers would expect. There was a heavy reliance on Zookeeper to ensure cluster state was synchronized at each end of the pipe – consumers and producers. A great breakdown of the message flow is provided by Roopa Kushtagi in the article, “Understanding the Evolution of ZooKeeper in Apache Kafka” which is a recommended (but not required) read:
- Producers connected to ZooKeeper to discover brokers in the cluster before sending messages.
- Once the producer had the latest cluster metadata, it could start sending messages to brokers. However, the producer still needed to go through ZooKeeper to coordinate the election of a controller broker and to ensure that all of the producers had the same view of the cluster state.
- Consumers also connected to ZooKeeper to identify brokers and gather information about topics they subscribed to before polling brokers for messages.
This flow achieved the Kafka design goals of a distributed event-driven messaging system with consensus, but there were several glaring issues. Most importantly, there were many redundant routes through Zookeeper which added to system complexity and limited scalability. Consumer groups and consumer offsets were also managed directly within Zookeeper at this time, which added to the need for Zookeeper coordination.
Zookeeper with Modern Kafka
Major changes in modern Kafka versions using Zookeeper are consumer offset tracking and consumer group coordination, now performed directly within the Kafka cluster with internal topics (e.g. “__consumer_offsets”). Zookeeper was not designed to handle high-throughput writes, as can be the case with consumer offsets. With these changes, consumers have a reduced reliance on Zookeeper and are less likely to face scaling issues.
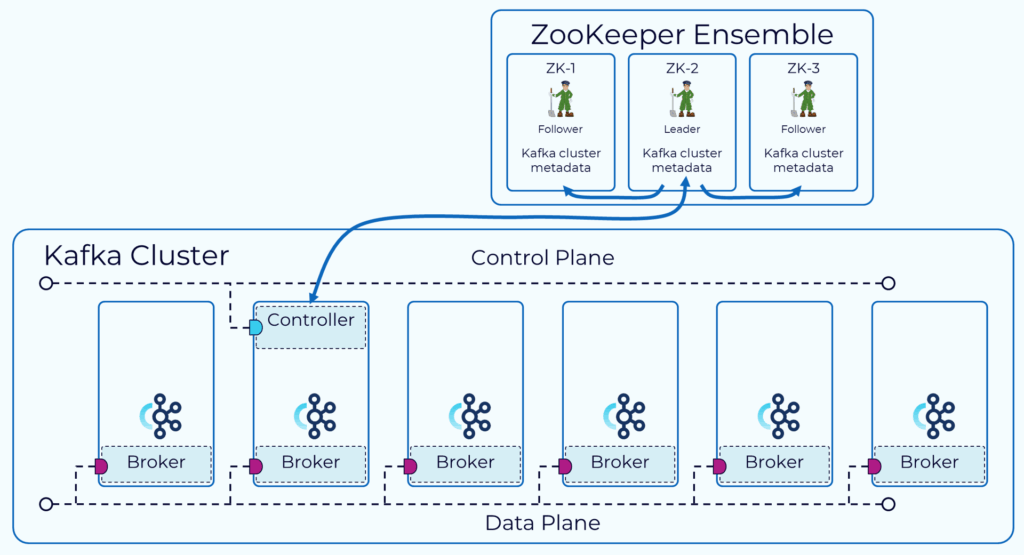
Until this point, Zookeeper has been described in basic terms and domain-specific implementation details have been avoided. The reason is simple: the details are irrelevant to most people, and an abstract high-level understanding will usually suffice. However, for any Kafka operators (or hobbyists) who are interested, we will go into the implementation details of Zookeeper here. It is time to take a look under the hood; how does Zookeeper actually manage Kafka metadata?
At its core, all Zookeeper clusters (even those unrelated to Kafka) are built on a filesystem-like hierarchy of “ZNodes.” Each of these ZNodes may represent a different form of metadata (e.g. brokers, topics, the controller broker). There are several types of ZNodes.
Ephemeral ZNodes are nodes that disappear when the client session ends. For Kafka metadata, this is useful for tracking broker availability and election of the current controller broker. In older versions of Kafka, ephemeral ZNodes were also used for managing consumer group members (managed by internal topics in newer versions).
Persistent ZNodes are nodes that remain until they are deleted, even if the client session ends. These are the node type of choice for most permanent and long-lasting configurations. In relation to Kafka metadata, persistent metadata includes topic configurations and partition assignments. Persistent topic configurations are paramount for permanently saving topic names, retention periods, and cleanup policies (among other properties) – even in the case of cluster downtime. Similarly, permanent persistence of partition assignments will help brokers to continue their work smoothly upon restart.
Sequential ZNodes in Zookeeper append a monotonically increasing counter to node names, ensuring a guaranteed order of creation. These can be either ephemeral or persistent. While they’re useful for distributed coordination patterns like locks and queues, Kafka’s controller election specifically uses a regular ephemeral ZNode at “/controller” with atomic creation semantics rather than sequential ZNodes.
There is another important function of Zookeeper to understand: watches. ZNodes of different types work together to create the full Kafka metadata hierarchy, but watches allow brokers to subscribe to changes on each registered ZNode. Watches are a core facet of Zookeeper because they allow brokers to be notified of ZNode changes, instead of constantly polling for those changes. For example, the “/brokers/ids” watch is notified when brokers join or leave the cluster, and the “/controller” watch is notified when there is a controller broker election.
Through ZNodes and watches, the full picture of Kafka metadata with Zookeeper becomes apparent. ZNodes, both temporary and permanent, are responsible for persisting metadata: topics configurations, partitions assignments, cluster configurations, active brokers, and the current controller broker. Meanwhile, watches allow brokers to subscribe to specific changes on these ZNodes.
Kafka Raft (KRaft)
Kafka Raft, also called KRaft, is a consensus protocol that was built for and by Kafka. Unlike Zookeeper, which fit general requirements but had operational challenges thanks to being a separate distributed system, KRaft was created to fit the exact needs of Kafka clusters and their metadata.
A Short KRaft History
KRaft was introduced in KIP-500, and a short look at its proposal shows how much effort and design went into its creation. Kafka developers needed to implement a Kafka-first approach to vote-based consensus, compatibility with clients, management of broker states, formats of metadata, etc. To address the issue of consensus, the Raft algorithm was chosen as a base due to its ability to reliably distribute logs and handle votes with fault tolerance. Over the course of several years, KIP-500 was incrementally improved until KRaft support reached stability.
In version 3.5 of Kafka, Zookeeper was deprecated in favor of KRaft. Later, as of version 4.0, Zookeeper support was completely dropped and is no longer supported.
KRaft Configuration Management
Zookeeper and KRaft are both responsible for persisting metadata, but their mechanisms for performing this duty are much different. Zookeeper is an external distributed system and stores metadata within “ZNodes”. In contrast, KRaft uses a distributed log format that is similar to Kafka topics.
Importantly, KRaft is able to run on existing Kafka brokers and within the same cluster. A node may act simultaneously as a KRaft controller and Kafka broker (combined mode), or independently as broker-only or KRaft-only (dedicated mode).
From the perspective of configuration management, this provides significant improvements to operator maintenance and cohesion. For example, if there are SSL changes to requirements for the cluster, previous incarnations would require different properties for Zookeeper and KRaft because they were developed separately and naturally chose different environment variables. That is not the case for KRaft; properties are generally shared between KRaft and broker configurations because they share the same configuration frame.
KRaft controllers are able to accept most broker properties, but they also rely on several properties that are specific to KRaft. For example, a “process.roles” property is required to identify a node as a Kafka broker, KRaft controller, or both. The “controller.quorum.voters” property is a list of KRaft controller URLs; it is required for all brokers and KRaft controllers to manage metadata consensus.
KRaft Metadata Structure
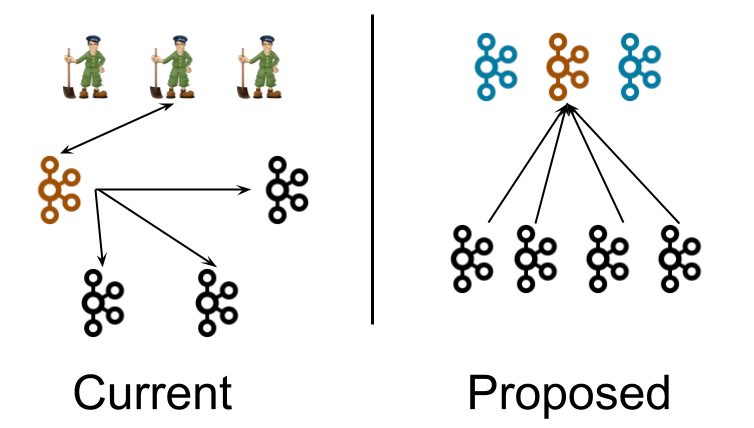
The controller nodes elect a single leader for the metadata partition, shown in orange. Instead of the controller pushing out updates to the brokers, the brokers pull metadata updates from this leader. That is why the arrows point towards the controller rather than away.
Note that although the controller processes are logically separate from the broker processes, they need not be physically separate. In some cases, it may make sense to deploy some or all of the controller processes on the same node as the broker processes. This is similar to how ZooKeeper processes may be deployed on the same nodes as Kafka brokers today in smaller clusters. As per usual, all sorts of deployment options are possible, including running in the same JVM.
The controller nodes comprise a Raft quorum which manages the metadata log. This log contains information about each change to the cluster metadata. Everything that is currently stored in ZooKeeper, such as topics, partitions, ISRs, configurations, and so on, will be stored in this log.
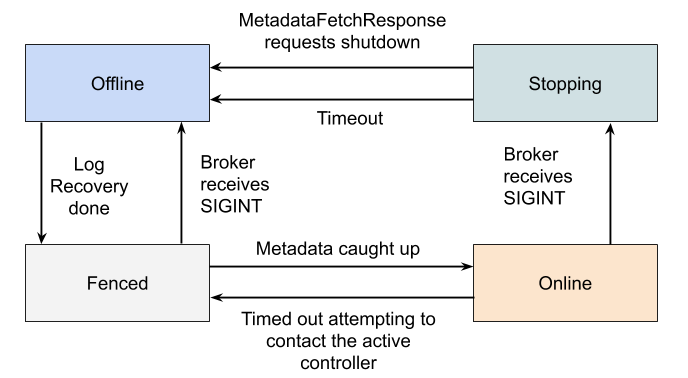
There were several considerations to match existing Zookeeper functionality. One of these considerations was the broker state machine – tracking the status of brokers. The above diagram illustrates how this was accomplished. By using a heartbeat mechanism paired with an KRaft-elected leader, the leader is able to remove brokers that have not sent a heartbeat in a long enough time.
The metadata log of Kafka is formatted much differently than Zookeeper. Zookeeper uses “ZNodes”, and these are internally distributed in a filesystem-like format. This does not occur with KRaft; instead, each metadata change is stored in a topic-like log (named “__cluster_metadata”) that is distributed among KRaft controllers in the quorum. The leader KRaft controller is responsible for this distribution and synchronization. If a KRaft controller goes offline, it will be synchronized when it comes back online.
Review
In this post, we reviewed what KRaft is and how it is used with Apache Kafka. We discussed its predecessor, Zookeeper, and why it was originally chosen to manage metadata. We discussed how both of these systems work internally: Zookeeper using a filesystem-like structure of ZNodes, and KRaft using an internal topic-like structure.
If you enjoyed this content, and like the topics that were discussed here, feel free to follow us on LinkedIn!
